C Données carroyées
CA Découper les carroyages selon les limites administratives
Nous allons reprendre les carroyages de la table r_rfl09_laea1000 importée dans le module Import-Export pour produire une nouvelle table, r_rfl09_cut_dpt , où les carreaux à cheval sur 2 départements ou plus sont coupés en morceaux qui épousent la frontière.
transformer r_rfl09_laea1000 dans le SRID de departementsou bien
transformer les departements dans le SRID de r_rfl09_laea1000 ?
- Faire la transformation de SRID nécessaire sans remplacer les géométries d’origine , mais en ajoutant une colonne geom_xxxx (où xxxx est le SRID)
- (il s’agit du même type d’opération que dans le module Type GEOMETRY → Reprojeter une table entière )
Comment penser la jointure ?
Les départements servent à découper les carreaux
Pour chaque carreau , on produit autant de bouts de carreaux que de départements qu’il intersecte
Chaque bout de carreau est l’intersection entre un carreau et un département
Écrire la jointure avec les champs SELECT suivants :
- r_rfl09_laea1000.ogc_fid AS carreau
- departements.code_dpt
- ind_carreau qui est la valeur d’origine de r_rfl09_laea1000.ind
- pct_aire , rapport de l’aire de l’intersection sur l’aire du carreau entier
- la géométrie résultant de l’intersection entre le carreau et le département AS geom
Indices :
- la condition de jointure (ON ) est la pour restreindre la jointure (l’intersection) aux combinaisons qui intersectent (on ne veut pas d’intersections vides)
- c’est une jointure INNER car on ne conçoit pas de carreau en dehors de tout département
- il n’y a pas de condition WHERE
- il est
impensable
d’exécuter la jointure d’intersections sans avoir au préalable créé les index spatiaux sur les champs géométriques intersectés - ... car sans index, PostGIS doit tester une à une toutes les combinaisons, soit 375 279 carreaux avec 97 départements, c’est-à-dire 36 402 063 (36 millions !) d’intersections.
- → faire EXPLAIN SELECT pour vérifier que la condition d’intersection exploite l’index (Index Cond: (geom && [...]) )
- Même avec index, la requête peut durer 20-30 minutes. Pour des essais, restreindre à quelques départements (ex: WHERE code_dpt IN (’75’, ’92’, ’93’, ’94’) ).
Créer la table en exécutant la requête précédée par CREATE TABLE r_rfl09_cut_dpt AS
- Puis ajouter un index spatial à cette nouvelle table, pour que la navigation QGIS soit fluide
- Afficher la couche sur QGIS
CB Grouper par territoire et appliquer la somme pondérée par la quote-part de surface
Reprendre la requête précédente en groupant par departements.code_dpt pour produire la table departements_popul listant les départements avec les colonnes :
- code_dpt issu de departements.code_dpt
- geom issu de departements.geom
- popul calculé de la somme des indices de population (r_rfl09_laea1000.ind ) des morceaux de carreaux intersectant le département pondérés par leur quote-part d’aire dans l’aire du carreau d’origine
CC Produire la carte des stocks de population
L’applat de couleurs (chloroplethe) n’est pas un mode de représentation cartographique adapté à un stock, car l’importance du phénomène serait doublement représenté (variable de couleur et taille de la surface). Il s’agit là de règles de sémiologie. Pour des stocks (de population ou autre), il convient d’utiliser des symboles proportionnels centrés sur le centroïde du territoire dont ils représentent la variable.
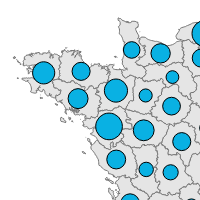
Nous allons donc utiliser produire une carte avec 2 couches :
- Au fond : les polygons des départements, en bordure gris foncé, remplissage gris clair, bordure de 0.1 millimètre
- Par dessus : disques de couleur bleu foncé, centrés sur le centroïde de leur département et dont l’aire est proportionnelle à la quantité de population du département.
Sachant que :
- Les cercles plus petits doivent s’afficher par dessus les plus gros, donc il faut faire un tri dans la requête par taille de cercle
- Le centroïde doit être calculé dans la requête SQL (et non pas dans QGIS)
- On produira côté requête le diamètre à appliquer aux cercles, en millimètres écran (pas en unités de carte )
- On demandera à QGIS un style Symbole unique , Symbole simple , un disque bleu ciel à fine bordure noire et de diamètre proportionnel au champ size qu’on aura produit dans la requête
- La taille du symbole, qui sert de facteur constant de taille, sera à ajusté pour une carte belle, où les départements restent visibles avec une taille de disques correcte.
- On fera la vue departements_popul_centroid à partir de la table departements_popul
- Pour que QGIS traite correctement la vue, il faut contraindre le type de la géométrie produite : utiliser le casting ::geometry(Point,4326)
CD Produire la carte des densités de population
De la même façon que pour CB , créer la vue departements_popul_ratio reprenant les colonnes de departements_popul en ajoutant la colonne popul_densite représentant la densité de population en nombre d’habitants par kilomètre-carré dans la projection Lambert 93 .
- Dans QGIS , faire la carte de densité par Style gradué sur la colonne popul_densite en 5 classes divisées en Quantiles (effectifs égaux)